CPU 보안 취약점을 공격하는 아주 구체적인 원리
멜트다운, 스펙터 페이퍼 읽기
지난 5월 인텔 CPU의 새로운 보안 취약점이 보고됐다. MDS(Microarchitectural Data Sampling)라고 불리는 이 취약점은 2018년 초 보고된 멜트다운(Meltdown), 스펙터(Spectre) 취약점과 달리 CPU 내부 3개의 버퍼(Line Fill Buffers, Load Ports, Store Buffers)로부터 사적인 데이터를 유출할 수 있다. MDS에 대해 공부하기 전 (뒤늦게) 멜트다운과 스펙터에 대해 알아보기로 했다.
Meltdown

멜트다운은 인텔 프로세서에서 발견된 취약점이다. 공격자는 비순차적 명령 실행(Out of Order Execution)의 맹점을 이용해 접근할 수도, 접근해서도 안되는 데이터에 접근하고, 캐시와 같은 사이드 채널을 통해 정보를 알아낸다.
Background
비순차적 명령 실행에 대해 다루기 전에 파이프라인(Pipeline)에 대해 간단히 이해해야 한다. 우선 프로세서가 명령을 처리하는 과정은 다섯 부분으로 나눌 수 있다.
- IF (Instruction Fetch): 바이너리 형식의 명령을 메모리에서 CPU로 가져온다.
- ID (Instruction Decode): 명령의 종류를 알아내고 레지스터에 입력한다.
- EX (Execute): 명령의 데이터를 연산한다.
- MEM (Memeory): 필요한 경우 메모리에 접근한다.
- WB (Write Back): 연산 결과를 다시 레지스터에 입력한다.
하드웨어 레벨에서 프로세서의 데이터패스(Datapath)를 도식화하면 아래 그림처럼 된다:
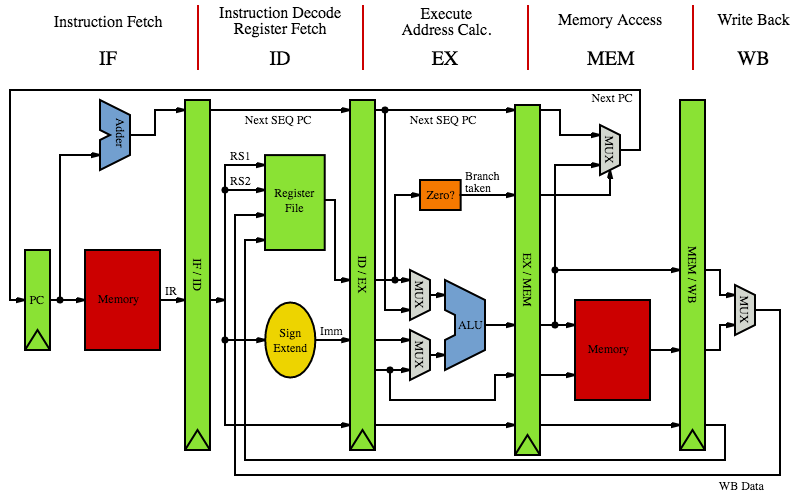
메모리에서 프로세서로 바이너리 형식 데이터를 가져와 명령의 종류를 알아내고, 값을 적절한 레지스터에 저장한다. (컴퓨터가 코드를 읽는 아주 구체적인 원리에서 바이너리 데이터를 읽는 방식을 간단히 다뤘다.) 명령이 조건문이라면 레지스터의 값이 참인지 확인하는 과정을 거쳐 다른 코드로 점프하고, 조건문이 아니라면 ALU(Arithmetic Logic Unit)가 연산을 수행한다. 이어서 명령에 따라 메모리의 데이터를 가져오거나, 메모리에 데이터를 입력한다. 메모리에 접근할 필요가 없는 명령이라면 연산 결과를 다시 레지스터에 저장한다.
만약 한 명령이 ID 단계에 있다면 레지스터만 동작하고, 메모리나 ALU같은 요소들은 사용되지 않을 것이다. 프로세서의 일부만 사용하는 것은 비효율적이다. 한 명령이 ID 단계에 있을 때 다른 명령은 IF, 또 다른 명령은 EX 단계를 거칠 수 있다. 이렇게 병렬적으로 명령을 실행할 수 있도록 만든 것이 파이프라인(Pipeline)이며, 위 그림에서는 4개의 녹색 막대로 표현되었다. 파이프라인은 병렬적으로 실행되고 있는 각 단계의 명령들이 서로 데이터를 공유할 수 있도록 해준다.
파이프라인 덕분에 프로세서는 한 클럭 사이클(Clock cycle)에 최대 5개 명령을 동시에 실행할 수 있다.
+---+------+------+------+------+------+------+------+------+------+
| 1 | IF | ID | EX | MEM | WB | |
+---+------+------+------+------+------+------+------+------+------+
| 2 | | IF | ID | EX | MEM | WB | |
+---+------+------+------+------+------+------+------+------+------+
| 3 | | IF | ID | EX | MEM | WB | |
+---+------+------+------+------+------+------+------+------+------+
| 4 | | IF | ID | EX | MEM | WB | |
+---+------+------+------+------+------+------+------+------+------+
| 5 | | IF | ID | EX | MEM | WB |
+---+------+------+------+------+------+------+------+------+------+다섯 번째 클럭 사이클에서 명령1이 WB 단계에 있을 때 명령2는 MEM, 명령3은 EX, 명령4는 ID, 명령5는 IF 단계를 거친다. 이것만으로 상당히 효율적이지만, 성능이 저하되는 상황도 있다.
1: lw $t0, 0($sp)
2: lw $t1, 4($sp)
3: and $s1, $t0, $t1
4: add $s2, $t0, $s1
5: addi $s3, $t0, 20메모리에서 데이터를 가져와 $t0 레지스터에 저장하는 명령1과 $t0를 이용해 덧셈을 하는 명령3, 명령4, 명령5는 모두 의존성을 가지고 있다. 한편 $t1에 메모리의 데이터를 저장하는 명령2는 $t1을 이용해 덧셈을 하는 명령3과 의존성을 가진다.
순차적으로 명령을 실행한다면 1, 2, 3, 4, 5 순서가 맞다. 하지만 이렇게 하면 메모리에서 데이터를 로드하는 시간, 연산 결과를 레지스터에 작성하는 시간 동안 지연이 발생한다.
+---+------+------+------+------+------+------+------+------+------+------+------+------+------+
| 1 | IF | ID | EX | MEM | WB | |
+---+------+------+------+------+------+------+------+------+------+------+------+------+------+
| 2 | | IF | ID | EX | MEM | WB | |
+---+------+------+------+------+------+------+------+------+------+------+------+------+------+
| 3 | | IF | ID | | EX | MEM | WB | |
+---+------+------+------+------+------+------+------+------+------+------+------+------+------+
| 4 | | IF | ID | | EX | MEM | WB | |
+---+------+------+------+------+------+------+------+------+------+------+------+------+------+
| 5 | | IF | ID | EX | MEM | WB |
+---+------+------+------+------+------+------+------+------+------+------+------+------+------+명령 5는 명령 1과 의존성이 있지만, 다른 명령들과는 의존성이 없다. 따라서 명령의 실행 순서가 달라져도 같은 결과를 보장할 수 있다.
+---+------+------+------+------+------+------+------+------+------+------+------+
| 1 | IF | ID | EX | MEM | WB | |
+---+------+------+------+------+------+------+------+------+------+------+------+
| 2 | | IF | ID | EX | MEM | WB | |
+---+------+------+------+------+------+------+------+------+------+------+------+
| 3 | | IF | ID | | EX | MEM | WB | |
+---+------+------+------+------+------+------+------+------+------+------+------+
| 5 | | IF | ID | EX | MEM | WB | |
+---+------+------+------+------+------+------+------+------+------+------+------+
| 4 | | IF | ID | EX | MEM | WB |
+---+------+------+------+------+------+------+------+------+------+------+------+1, 2, 3, 5, 4 순서로 실행하니 2 클럭 사이클이 줄었다. 이처럼 프로세서는 성능을 위해 코드의 순서를 바꾼다. 순서를 바꿔 실행하는 것을 비순차적 명령 실행이라고 하며, 인텔은 의존성이 없는 명령을 같은 클럭 사이클에 실행하는 수퍼스칼라(Superscalar) 기술을 사용한다. 가령 n-way 수퍼스칼라의 경우 같은 클럭 사이클에 IF 단계의 명령을 n개 동시 처리할 수 있다.
Attack Overview
멜트다운 취약점 공격은 기본적으로 실행해서는 안되는 코드를 비순차적 실행으로 실행시키고, 이때 캐시에 올라간 데이터에 접근해 사적인 정보를 알아내는 방법을 사용한다.
A Toy Example
비순차적 실행의 취약점을 보여주는 간단한 예시 코드를 보자:
raise_exception();
// the line below is never reached
access(probe_array[data * 4096]);data는 접근할 수 없는 메모리 공간을 가리키는 값이며, 4096은 페이지 크기다. 공격자는 data에 4KB 페이지 사이즈를 곱해 data번째 페이지의 베이스 주소에 접근한다. (페이지란 메모리를 효율적으로 사용하기 위해 프로세스를 여러 조각으로 나눈 단위이다.) 즉, 공격자는 probe_array 배열을 이용해 접근할 수 없는 공간에 접근을 시도한다.
위 코드에서는 raise_exception이 항상 예외를 일으키기 때문에 이론적으로 access 함수는 절대로 실행되지 않는다. 그런데 비순차적 명령 실행에 의해 raise_exception 함수보다 access 함수가 먼저 실행되어 허용되지 않은 메모리 공간에 접근할 수 있다.
예외가 발생하면 프로세서는 비순차적으로 실행한 명령을 취소하지만, 이때는 캐시에 이미 시크릿 바이트(Secret byte) data * 4096이 올라간 상태다. 따라서 캐시에 저장된 시크릿 바이트를 찾으면 데이터를 알 수 있다. (캐시에 관한 보다 자세한 내용은 캐시가 동작하는 아주 구체적인 원리를 참고.) 이제 공격자는 프로세스의 모든 페이지에 하나씩 접근하며 시간을 측정한다.
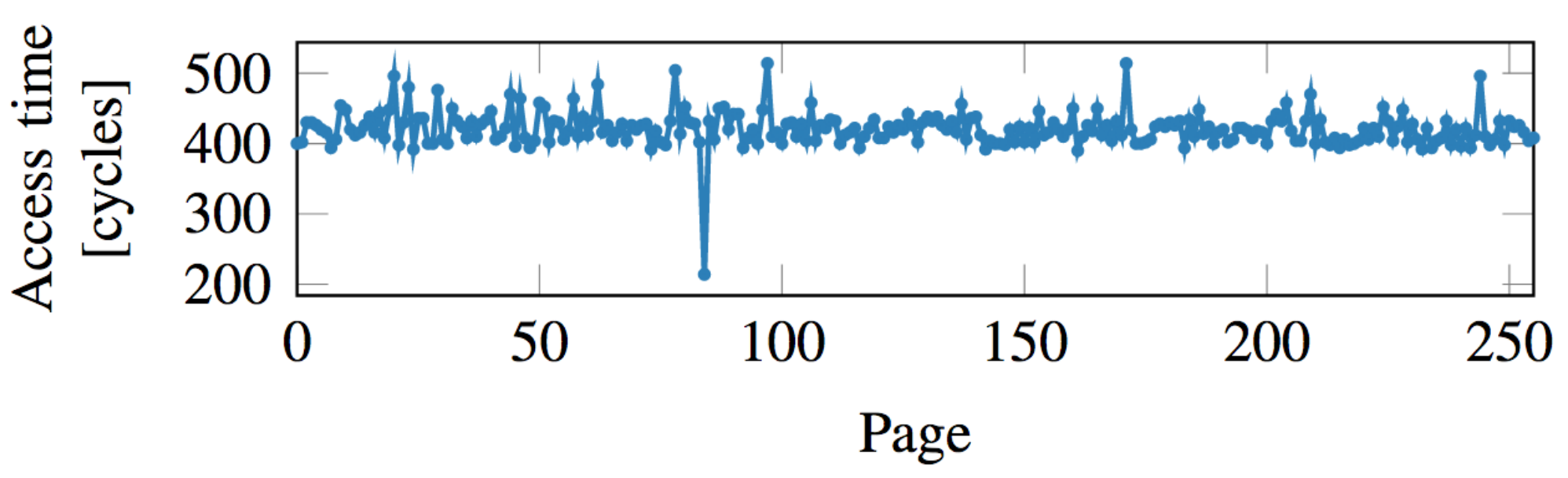
페이지의 베이스 주소(Base address)가 0 * 4096인 것부터 1 * 4096, 2 * 4096, ... , 255 * 4096까지 접근하면 캐싱된 페이지만 접근 시간(Access time)이 유난히 짧은 것을 볼 수 있다. 이것이 공격자가 노리는 data번째 페이지이며, 이를 통해 data의 값을 알게 된다. 만약 공격자가 노리는 data의 값이 'A’였다면 65번째 페이지에 접근하는 시간이 가장 짧게 나타났을 것이다. (아스키 코드상 'A’의 10진수 값이 65이기 때문이다.)
캐시를 비우고(Flush) 읽는(Reload) 방식으로 정보를 알아내는 공격법을 Flush-Reload 공격법이라고 한다. 앞서 캐시를 비우는 과정은 생략했는데, 만약 따로 캐시를 비우지 않으면 타겟 데이터가 어떤 것인지 분간할 수 없었을 것이다.
Attack Description
멜트다운 취약점 공격의 핵심 코드를 x86 어셈블리 명령으로 표현하면 아래와 같다:
; rcx = kernel address, rbx = probe array
xor rax, rax
retry:
mov al, byte [rcx]
shl rax, 0xc
jz retry
mov rbx, qword [rbx + rax]rcx 레지스터는 커널 메모리 주소를 담고 있으며, rbx 레지스터는 시크릿 바이트를 찾기 위한 배열로 사용한다.
- 먼저
mov al, byte [rcx]명령으로 커널 메모리에서 특정 값(rcx)을 로드해al로 표현된rax레지스터에 저장한다.rax레지스터는 x86 아키텍처에서 사용되는 64비트 범용 레지스터이며,al은rax레지스터의 하위 8비트 서브레지스터(Subregister)다. 누산기 레지스터(Accumulator register)라고 부르는rax레지스터는 산술 연산의 결과를 저장할 때 사용한다. - 유저 모드(User mode)에서는 커널 메모리에 접근할 수 없기 때문에 예외가 발생하고, 실행 결과는 반영되지 않은 채 취소된다. 예외가 발생하면 다음 명령들이 실행되지 않아야 하지만 비순차적 명령 실행에 의해 실제로는 다음 명령들이 실행될 수 있다.
- 비순차적 명령 실행으로 다음 명령인
shl rax, 0xc명령을 실행하면rax레지스터의 값에 페이지 사이즈인0xc(4096B, 4KB)를 곱한다. - 이어서
mov rbx, qword [rbx + rax]명령을 통해rbx의 베이스 주소에rax * 0xc를 더하고, 이 결과를rbx레지스터에 저장한다.rbx레지스터는 베이스 레지스터(Base register)로, 스택의 베이스 주소를 가리킨다. rbx레지스터에는rbx + rax * 0xc가 저장되어 있다. 즉,rax번째 페이지의 베이스 주소가 저장되어 있는 것이다.- 예외가 발생했기 때문에 위 과정은 모두 취소될 것이다. 그런데 실제로는
rax * 0xc에 접근했기 때문에 해당 값이 L1 캐시에 올라간다. - 앞선 예시에서 봤듯이 공격자는 256개 페이지를 모두 훑으면서 접근 시간을 측정한다.
rax번째 페이지는 캐싱되어 있기 때문에 특히 접근 시간이 짧다. 이를 통해 공격자는 비밀값rax를 알게 된다.
멜트다운 취약점은 유저모드에서 커널 메모리를 무단으로 참조할 수 있는 매우 심각한 취약점이다. 성능 향상을 위한 비순차적 명령 실행 기법으로 인해 발생한 취약점이기 때문에 이를 해결하기 위해서는 성능 저하가 불가피하며, 동시에 프로세서 레벨의 취약점이기 때문에 근본적인 문제를 해결하기 위해서는 하드웨어 설계 차원에서도 조치가 필요하다.
Spectre

스펙터는 인텔, AMD, ARM 프로세서에서 발견된 취약점으로, 공격 기반 원리는 멜트다운과 비슷하다. 컴퓨터는 조건문을 실행할 때 어떤 조건에 부합할지 예측하고 실행하는데, 당연히 잘못된 예측을 하는 경우도 있다. 스펙터 취약점은 예측이 실패하는 상황을 노려 외부에서 접근해서는 안 되는 메모리 영역에 접근하는 방식으로 공격한다.
Background
조건문의 실행을 예측하는 것을 브랜치 예측(Branch prediction)이라고 한다.
for (int i = 0; i < 10; i += 1) {
result += 1;
}
printf("%d", result);루프를 돌 때마다 i < 10이 참인지 거짓인지 판단하고, 루프 내부를 실행해야 할지 루프를 빠져나와야 할지 결정해야 한다. 위 루프에서는 같은 결과가 연속적으로 반복되는데, 매번 판단 과정을 거치면 성능이 저하될 수밖에 없을 것이다.
조건문을 실행할지 말지 예측하고 미리 명령을 실행하면 성능을 개선할 수 있다. 이를 추측 실행(Speculation execution)이라고 한다. 브랜치 예측을 위한 간단한 방법으로 BHT(Branch History Table)가 있는데, 기본적으로 과거 기록을 통해 미래를 추측하는 개념이다. 직전 예측이 참이였는데 이 예측이 성공했다면 다시 참으로 예측해 명령을 실행하고, 예측이 실패했다면 거짓으로 예측해 명령을 건너뛰는 식이다. 예측이 실패할 경우 미리 실행한 명령을 되돌려야 한다.
Attack Overview
스펙터 취약점은 브랜치 예측의 실패를 이용해 공격할 수 있다. 공격자는 캐시 메모리 등 사이드 채널을 통해 다른 프로세스의 데이터에 접근한다. 원래 다른 프로세스의 메모리 공간에 접근해서는 안 되고, 접근할 수도 없지만, 브랜치 예측의 맹점을 이용하면 가능하다.
스펙터 공격의 첫 번째 유형은 특정 코드 블록을 실행해 데이터를 알아내는 것이다.
if (x < array1_size) {
y = array2[array1[x] * 4096];
}변수 x는 공격자가 설정하는 임의의 값으로, 배열의 메모리 범위를 넘는 값(Out of Bounds)을 넣는다. 따라서 array1[x]는 허용되지 않은 메모리 공간에 접근한다. 여기에 메모리에 있는 다른 페이지들을 읽기 위해 페이지 사이즈인 4096을 곱한다. 이때 공격자가 노리는 array1[x]를 시크릿 바이트(Secret byte) k라고 한다.
하지만 허용되지 않은 메모리 공간에 접근하면 세그먼트 폴트(Segment faults) 오류가 발생한다. 그래서 직접 해당 구문을 실행하지 않고 브랜치 예측을 이용한다.
- 프로세서가 조건문의 조건을 참으로 예측하도록 유도한다. (조건이 참인 상황을 여러 번 반복한다.)
- 이제 조건이 거짓이 되도록 하면 브랜치 예측이 실패한다. 코드상으로는 조건문 내부의 명령이 실행되지 않는 것처럼 보이지만, 추측 실행으로 인해 실제로는 명령이 실행된다.
- 예측이 실패했으므로 프로세서는 실행한 명령을 되돌린다.
y에는 아무런 값도 저장되지 않는다. - 명령이 취소되기는 했지만, 실제로는 데이터를 읽었기 때문에 취소된 명령이 접근한 데이터
k * 4096은 캐시에 올라가 남아있게 된다. 이때k는 허용된 메모리 범위를 넘는 값이기 때문에 해당 프로세스에서 접근할 수 없다. - 데이터에 직접 접근할 수 없기 때문에 공격자는 캐싱된 데이터를 이용한다. 공격자는
array2의 모든 요소를 무작위로 접근하면서 접근 시간을 측정한다. 접근 시간이 특히 짧은 데이터는 캐시에 저장되어 있다는 의미이므로, 이는 추측 실행으로 캐싱된k * 4096를 뜻한다. 멜트다운 취약점을 공격할 때 사용한 방법과 동일하다.
스펙터 취약점 공격을 위해서는 대상 프로세스 내에서 활용할 코드 블록인 가젯(Gadget)을 찾아야 할 뿐더러, 특정 메모리 주소를 가리키는 x를 설정하려면 공격 대상 머신의 VA(Virtual address)와 PV(Pysical address) 관계도 알아야 하기 때문에 실제로 공격하기는 어려운 점이 많다. 하지만 이 역시 심각한 취약점임은 틀림없다.
References
- ESTsecurity 알약 블로그, “인텔 CPU 취약점(Meltdown & Spectre) 상세분석”, 2018.
- Jann Horn, “Reading privileged memory with a side-channel”, Google Project Zero, 2018.
- Don Marshall et al., “x86 Architecture”, Microsoft Docs, 2017.
- Moritz Lipp et al., “Meltdown: Reading Kernel Memory from User Space”, 2018.
- Paul Kocher et al., “Spectre: Exploiting Speculative Execution”, 2018.
- SATAz, “멜트다운 취약점을 파헤쳐보자”, 2018.
- Silica Plant, “스펙터 멜트다운 공격”, 2018.
- 노규남, “CPU 취약점 종합 보고서”, 보안뉴스, 2018.